A simpler free LibreCrawl alternative
Both Crawly and LibreCrawl are free with unlimited crawling. The difference: Crawly is a native Mac app you download and use immediately. LibreCrawl needs a server. Crawly also includes Claude Code MCP, crawl comparison, and security header auditing.
Crawly vs LibreCrawl: what is the difference?
LibreCrawl is an open-source SEO crawler with impressive credentials: unlimited URLs, JavaScript rendering via Playwright, multi-session support, and a modern web-based interface. It is free and MIT-licensed. For teams who want a self-hosted crawler accessible from any browser, it is a legitimate option.
The catch is setup. LibreCrawl requires a server running Python, Playwright, and its own browser binaries before you can crawl a single page. That is fine for technically confident users or agencies with infrastructure, but it is a significant hurdle for individual SEOs who just need to audit a site now.
Crawly is a native macOS desktop app. Download it, open it, enter a URL. No server, no Python, no configuration. It also ships with features LibreCrawl does not have: crawl comparison for diffing audits over time, security header checks, hreflang validation, and a Claude Code MCP server that lets you query your crawl data in plain English from your terminal.
Crawly vs LibreCrawl
Both free, both unlimited. Different philosophy.
| Feature | Crawly Free | LibreCrawl |
|---|---|---|
| Price | Free | Free |
| Platform | Native macOS app | Self-hosted web app |
| Setup | Download and open | Server install required |
| Page limit | Unlimited | Unlimited |
| Claude Code MCP | ||
| Crawl comparison (diff) | ||
| Issues dashboard | Basic | |
| Security header checks | ||
| Hreflang audit | ||
| Saved crawl history | Per session | |
| JavaScript rendering | ||
| XML sitemap export | ||
| Open source | ||
| Self-hosted / team access |
Based on publicly available feature documentation as of May 2026.
See it in action
Native macOS. No server. No setup. Just crawl.
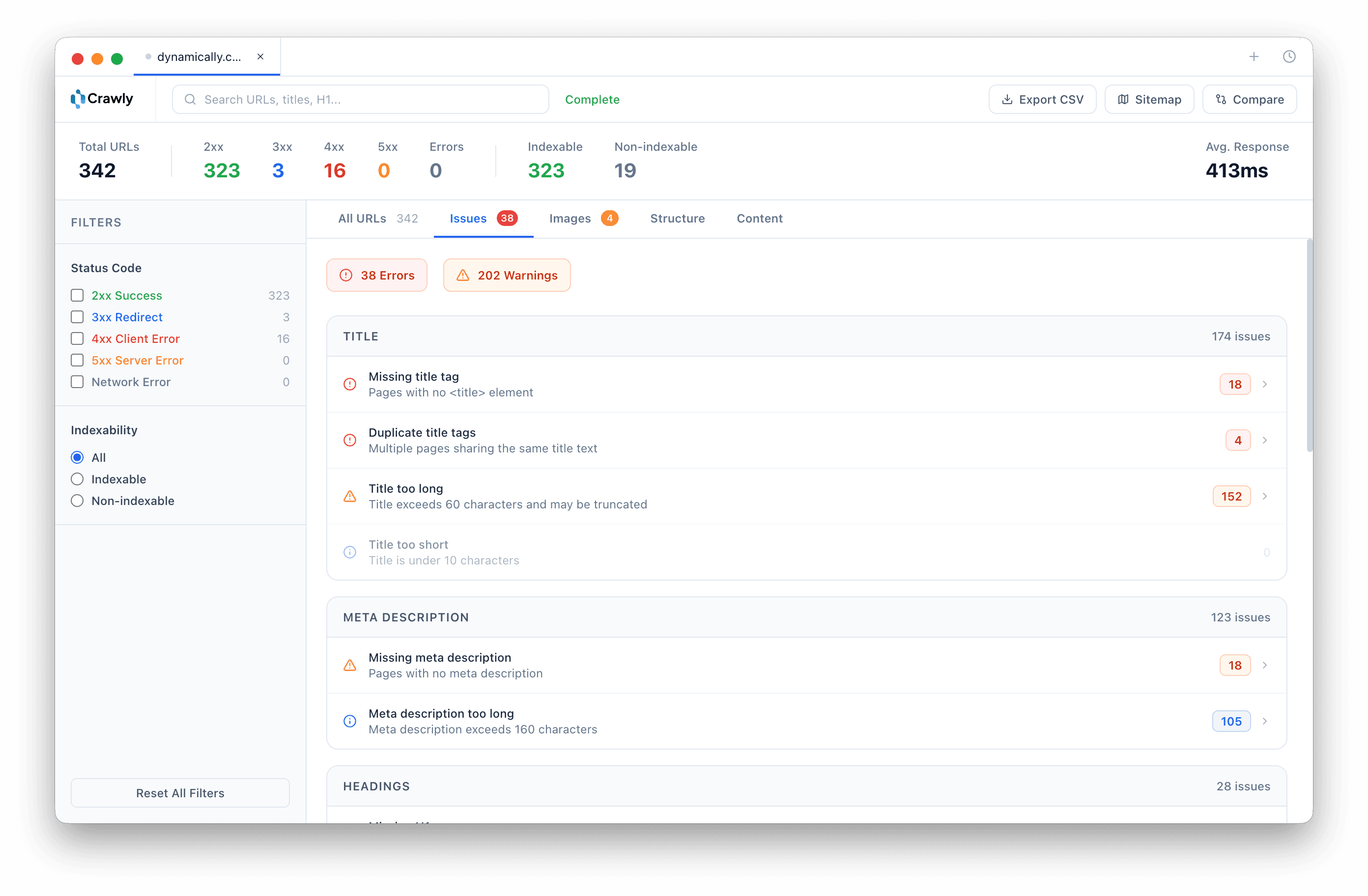
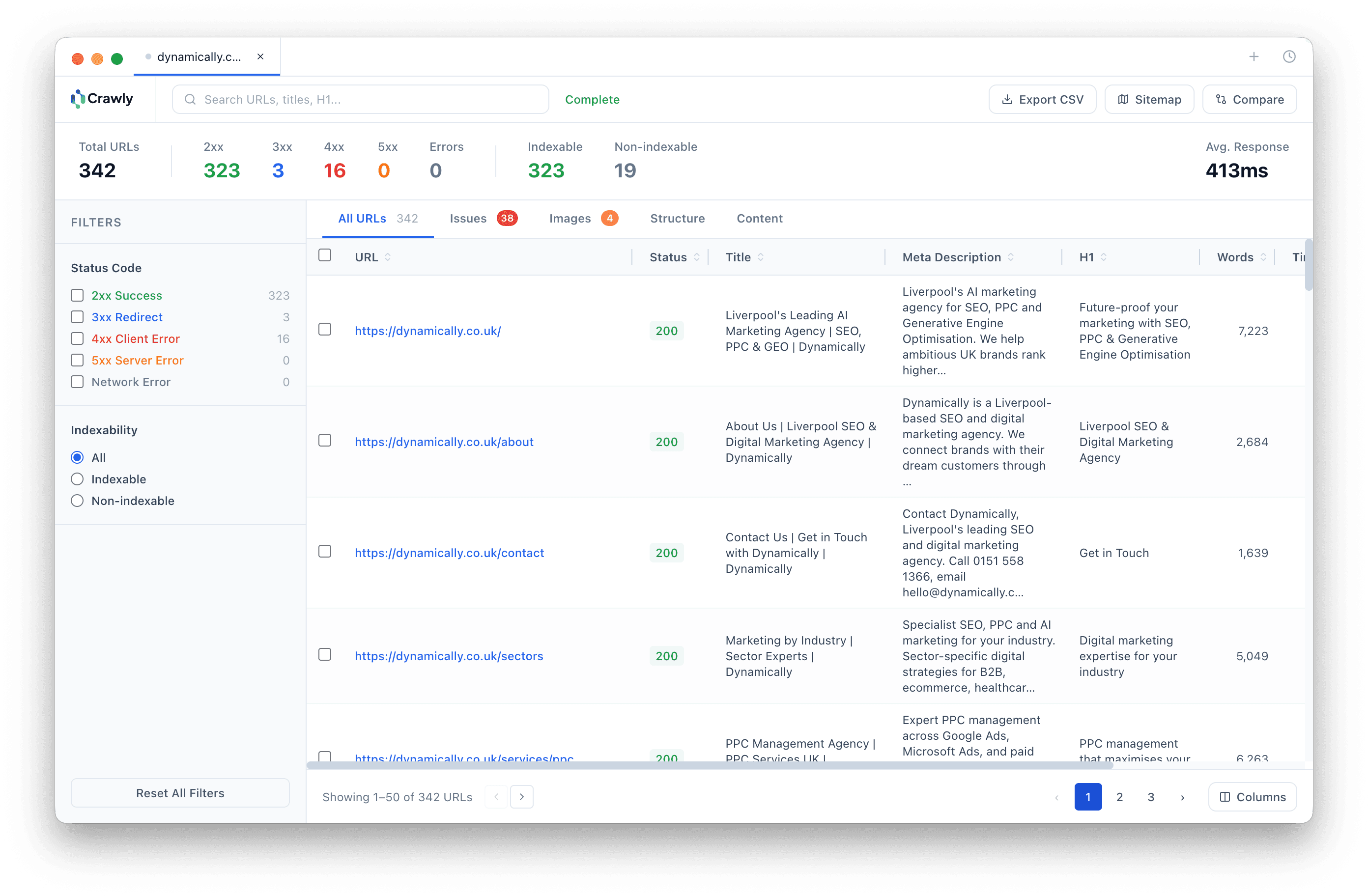
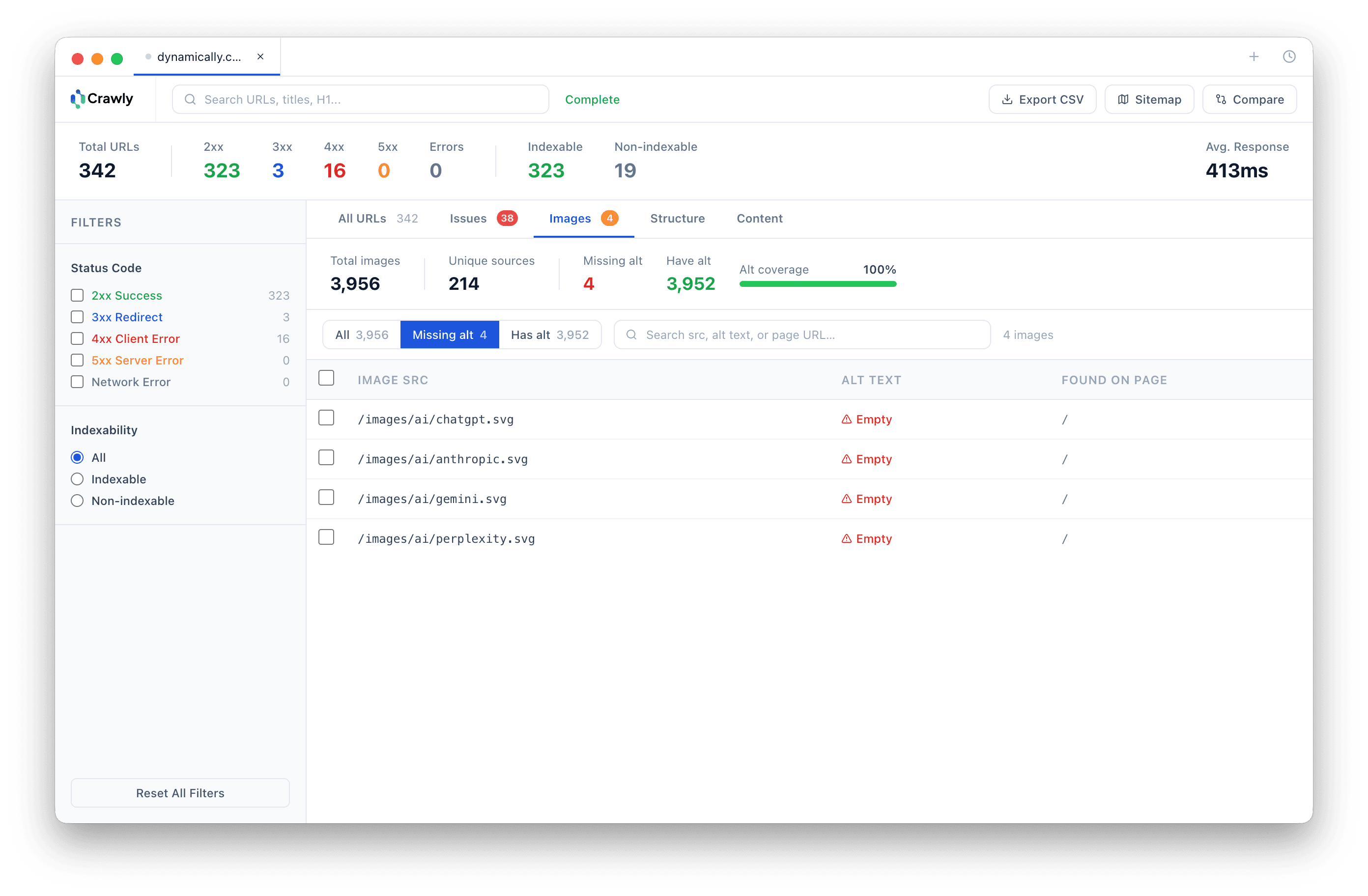
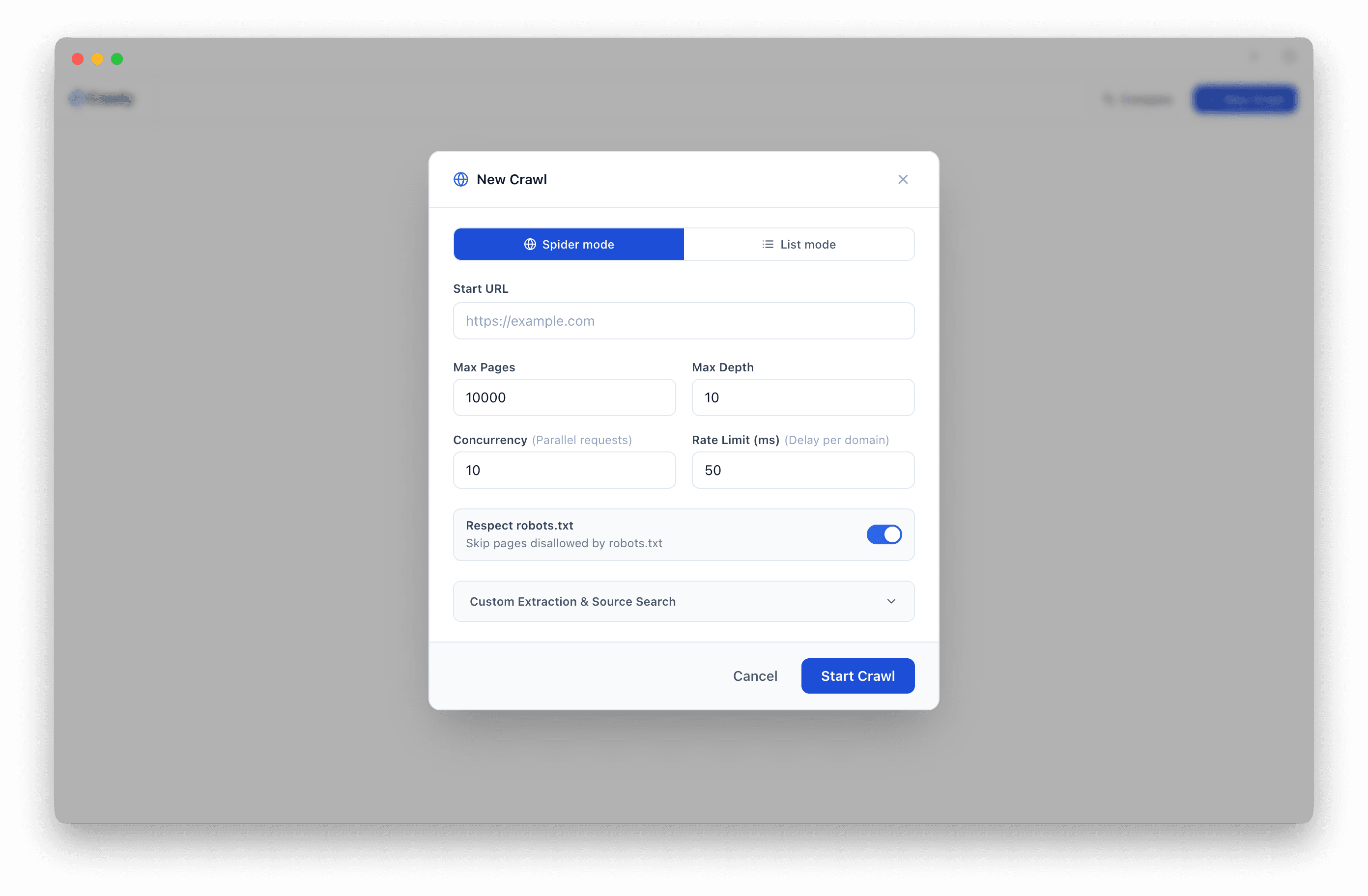
Frequently asked questions
- What is the main difference between Crawly and LibreCrawl?
- Both are free with unlimited URL crawling, but they are very different tools. Crawly is a native macOS desktop app - download it and you are crawling in seconds. LibreCrawl is a self-hosted web application that requires a server, Python, and Playwright to be set up before you can use it. For most individual SEOs and small teams, Crawly is the faster, simpler option.
- Does LibreCrawl have an MCP integration?
- No. LibreCrawl does not have any AI integration. Crawly ships with a built-in MCP server that connects to Claude Code, Cursor, Codex, and Windsurf. You can query your crawl data in plain English directly from your terminal.
- When would LibreCrawl be a better choice than Crawly?
- LibreCrawl is open source and self-hostable, which makes it useful for teams who want to share access to crawls via a browser, run crawls on a central server, or modify the tool to fit a custom workflow. If you need a self-hosted, team-accessible crawler with no software to install on individual machines, LibreCrawl is worth considering.
- Does Crawly support JavaScript rendering?
- Yes. Crawly renders JavaScript during crawls, making it suitable for auditing React, Next.js, and other JS-heavy sites.
- Is Crawly really free with no limits?
- Yes. Crawly is completely free to download and use with no URL cap, no licence fee, and no paid tier. There is no trial period.
Also comparing? Crawly vs Screaming Frog · Crawly vs Sitebulb · Crawly vs BeamUsUp · Crawly vs SEO Tracer · Crawly vs SEOnaut
Want to use Crawly with Claude Code? Read the Claude Code MCP setup guide

Start crawling smarter
Download Crawly for free. Connect to Claude Code via MCP and start auditing your site in minutes.
Download free